

A finales del año pasado perdí gran parte de los datos de mi empresa. Y no porque no tuviese backups, sino por ser poco paranoico. En mi caso, todos los datos de un servidor central se copiaban a otro disco por medio de incrementales. De ahí, se trasladaban a otra máquina por rsync, y esa otra máquina los enviaba a dos servidores diferentes en nuestro proveedor de hosting. En total, 4 copias diferentes en tres lugares geográficos diferentes.
Pero bastó un fallo eléctrico en la placa del servidor (que destruyó el disco original y el de copias), combinado con un bug en rsync (tenía una versión «algo» desfasada) que hacía que al no poder leer de origen asumiese que origen estuviese vacío, y eliminase en destino.
En resumen: casca la placa, se lleva por delante el disco original y el de copias. Esto pasa en un fin de semana, no estando físicamente en la oficina. El sábado salta el rsync automático desde el servidor B, que al no poder leer de A, asume que está vacio, y borra todo en B (bug de rsync). Esa misma noche, lanza los rsync contra los servidores online, al estar B vacío, vacía C y D. Cuando el Lunes llego a la oficina y voy tirando poco a poco del hilo, casi infarto.
Al final pude recuperar gran parte del trabajo gracias a la copia mensual que hago en un disco externo USB y me llevo a casa (aquella en la que menos confiaba!), pero la experiencia me sirvió para aprender que, en copias de seguridad, nunca hay demasiada paranoia y que, por supuesto, debía buscar otra opción para mis copias. Lo primero fue un RAID en los discos de ese servidor, y lo segundo un sistema de copias desatendidas en múltiples localizaciones, incrementales, y no dependientes de rsync, a quien desde ese fatídico día odio, desprecio e insulto cada vez que tengo ocasión.
Meet Amazon S3
El bajo coste de almacenamiento en la famosa nube S3 (Simple Storage Service) de Amazon, unido a su réplica automática en 3 diferentes localizaciones geográficas, lo hace ideal para el almacenamiento de copias de seguridad. Si además podemos hacer que sean automáticas, sin intervención del usuario, e incrementales, para poder volver N días al pasado sin problema, tenemos una solución robusta y fiable para poder despreocuparnos de esta tarea.
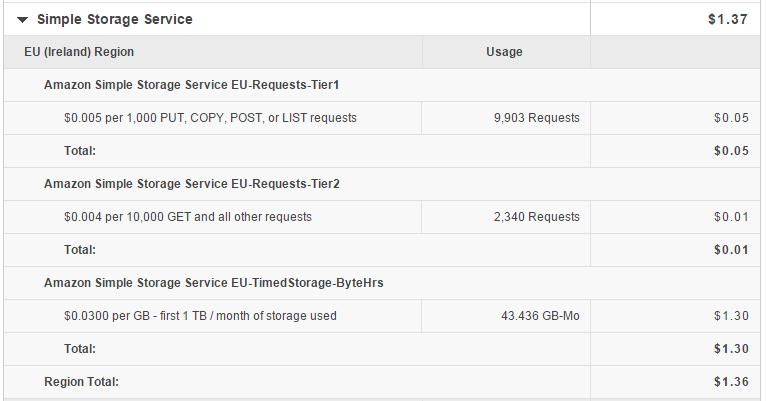
El coste es, como ya comentaba, ridículo, esta es mi factura por las copias de mis servidores dedicados del mes de Septiembre (unos 38 Gb de datos, 43 Gb contando las incrementales)
Para Windows disponemos de Duplicati, un software con interface de usuario, con lo que no me extenderé más en su uso; para linux y derivados, vamos a ver una implementación con Duplicity, un software de backup de sobrada eficiencia, y Duply, un frontend más «amigable» a Duplicity, que se apoya a su vez en la interface a AWS de Amazon python-boto
Ajustes en Amazon S3
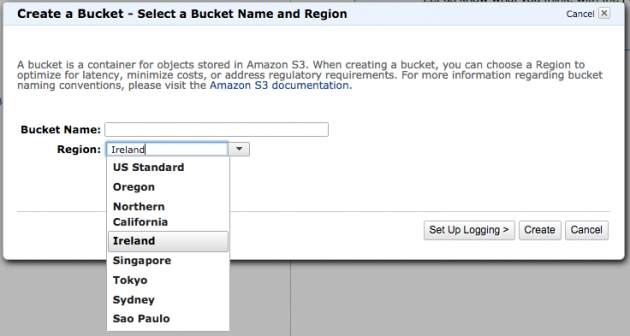
Lo primero es crear un bucket en Amazon, los pasos desde la consola de Amazon son bastante sencillos, crear el bucket, darle un nombre y elegir región (la más cercana a España es Irlanda) y crear un usuario de acceso y contraseña:
¿Estamos? Pues pasamos al servidor.
Instalación de dependencias
Empezamos por instalar las dependencias necesarias, en Ubuntu añadiremos el PPA de duplicity para disponer de la última versión, reemplazando «precise» por vuestra versión (lsb_release -c os dará la pista).
echo deb http://ppa.launchpad.net/duplicity-team/ppa/ubuntu precise main | sudo tee /etc/apt/sources.list.d/duplicity.list sudo apt-get update
sudo apt-get install duplicity duply python-boto
Configurando nuestra copia de seguridad
Ahora crearemos nuestra primera tarea de copias (podemos tener ilimitadas, con diferentes configuraciones). La denominaremos con el original nombre «cloud_backup»
duply cloud_backup create
Lo que nos devolverá un mensaje de confirmación similar a este:
Congratulations. You just created the profile 'cloud_backup'. The initial config file has been created as '/root/.duply/cloud_backup/conf'. You should now adjust this config file to your needs. IMPORTANT: Copy the _whole_ profile folder after the first backup to a safe place. It contains everything needed to restore your backups. You will need it if you have to restore the backup from another system (e.g. after a system crash). Keep access to these files restricted as they contain _all_ informations (gpg data, ftp data) to access and modify your backups. Repeat this step after _all_ configuration changes. Some configuration options are crucial for restoration.
Básicamente nos dice que ha creado el perfil de copias en ‘/root/.duply/cloud_backup/conf’ y que más vale que hagamos una copia de ese fichero por si la máquina «revienta» en el futuro, para ser capaces de restaurar dichas copias. En general esto no es necesario, siempre que tengamos a salvo nuestras credenciales de FTP, o en este caso, de Amazon AWS. Si lo es si además queremos encriptar dichas copias, una opción útil para los más paranoicos, pero que nos saltaremos en este tutorial básico.
Una vez tenemos nuestra primera tarea de copias creada, la configuraremos editando el fichero ‘/root/.duply/cloud_backup/conf’. Indico solo los parámetros más importantes que he modificado para este tutorial:
# no vamos a encriptar las copias GPG_KEY='disabled' #GPG_PW='_GPG_PASSWORD_' # Mi bucket, en Irlanda, por ejemplo, se llama "marcosbl-servers" # y la carpeta es el alias de cada máquina, cada una tiene una carpeta TARGET='s3://s3-eu-west-1.amazonaws.com/BUCKET/CARPETABUCKET' # Usuario de acceso al bucket, se gestionan desde la consola de Amazon TARGET_USER='XXXXXXXXXXXXXXXXXXXX' # Contraseña de acceso al bucket TARGET_PASS='XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX' # la carpeta base de donde vamos a realizar nuestras copias SOURCE='/' # Mantendremos nuestras copias antiguas un máximo de tres meses MAX_AGE=3M # Mantendremos dos copias completas en todo momentos, por si una se corrompiese MAX_FULL_BACKUPS=2 # Para evitar ralentización a la hora de leer las copias, subiremos el tamaño de paquete a 250Mb VOLSIZE=250 DUPL_PARAMS="$DUPL_PARAMS --volsize $VOLSIZE "
Una vez configurada nuestra tarea, debemos indicarle qué queremos incluir en nuestra copia de seguridad. Para ello podemos utilizar este truco: editaremos ‘/root/.duply/cloud_backup/exclude’indicando las carpetas que queremos incluir, con un «**» al final para indicarle que solo queremos dichas carpetas.
+ /root + /home/www + /home/vmail + /home/flashpolicy + /home/mysql + /home/radicale + /etc **
Si preferís un control más granular, podéis ver todas las opciones de include/exclude de Duply en http://duplicity.nongnu.org/duplicity.1.html en general basta con poner las rutas más profundas primero, tanto para inclusión como exclusión, y las menos profundas al final, o nos encontraremos con resultados extraños.
Creando nuestra primera copia
Una vez tenemos nuestra tarea configurada, y hemos indicado qué carpetas queremos salvaguardar, llega el momento de comprobar nuestra configuración:
duply cloud_backup backup --preview
Si nos parece que todo está correcto, es hora de lanzar nuestra primera copia:
duply cloud_backup backup
Tras el tiempo de rigor, nos dará unas estadísticas de resultado. En nuestro caso 90.831 archivos que ocupaban 18.8 GB han quedado salvaguardados de forma segura ocupando 7.07 GB en Amazon S3 (con un mareante coste total de unos 0.21€ al mes)
--------------[ Backup Statistics ]-------------- StartTime 1413942182.36 (Wed Oct 22 03:43:02 2014) EndTime 1413944638.15 (Wed Oct 22 04:23:58 2014) ElapsedTime 2455.79 (40 minutes 55.79 seconds) SourceFiles 90831 SourceFileSize 15921487361 (14.8 GB) NewFiles 90831 NewFileSize 15921487361 (14.8 GB) DeletedFiles 0 ChangedFiles 0 ChangedFileSize 0 (0 bytes) ChangedDeltaSize 0 (0 bytes) DeltaEntries 90831 RawDeltaSize 15905323958 (14.8 GB) TotalDestinationSizeChange 7593087053 (7.07 GB) Errors 0 ------------------------------------------------- --- Finished state OK at 04:25:41.234 - Runtime 00:42:39.534 ---
Si ahora lanzamos el comando de nuevo, al existir ya una copia completa, se realizará de forma automática una copia incremental, en este caso se han modificado entre las dos 48 ficheros, hay 17 nuevos y se han eliminado 3, con un incremento de tamaño de 183 Mb, que han sido salvaguardados en 39 segundos.
duply cloud_backup backup Last full backup date: Wed Oct 22 03:43:02 2014 --------------[ Backup Statistics ]-------------- StartTime 1413945201.72 (Wed Oct 22 04:33:21 2014) EndTime 1413945228.27 (Wed Oct 22 04:33:48 2014) ElapsedTime 26.55 (26.55 seconds) SourceFiles 90836 SourceFileSize 15785987879 (14.7 GB) NewFiles 17 NewFileSize 184389850 (176 MB) DeletedFiles 3 ChangedFiles 48 ChangedFileSize 811334194 (774 MB) ChangedDeltaSize 0 (0 bytes) DeltaEntries 68 RawDeltaSize 191377039 (183 MB) TotalDestinationSizeChange 188097319 (179 MB) Errors 0 ------------------------------------------------- --- Finished state OK at 04:34:00.248 - Runtime 00:00:39.395 ---
Podemos ver el historial de copias con el comando status, en nuestro ejemplo veremos la copia completa (con 29 volúmenes de 250 Mb) y la incremental que hemos lanzado a continuación (1 solo volumen es suficiente)
duply cloud_backup status Last full backup date: Wed Oct 22 03:43:02 2014 Collection Status ----------------- Connecting with backend: BotoBackend Archive dir: /root/.cache/duplicity/duply_cloud_backup Found 0 secondary backup chains. Found primary backup chain with matching signature chain: ------------------------- Chain start time: Wed Oct 22 03:43:02 2014 Chain end time: Wed Oct 22 04:33:21 2014 Number of contained backup sets: 2 Total number of contained volumes: 30 Type of backup set: Time: Num volumes: Full Wed Oct 22 03:43:02 2014 29 Incremental Wed Oct 22 04:33:21 2014 1 ------------------------- No orphaned or incomplete backup sets found. --- Finished state OK at 04:36:32.714 - Runtime 00:00:00.574 ---
Lanzando copias incrementales automáticas
Una vez realizada la primera copia, el sistema se encarga de realizar una incremental cada vez que llamemos a «duply cloud_backup backup». Como hemos indicado que no se guarden copias superiores a tres meses, al llegar esta antigüedad, se eliminaría la vieja copia y se realizaría una nueva completa, siempre que utilicemos este comando sin más. Para ello basta con añadir una linea a nuestro crontab, por ejemplo, cada día a las 2 AM
# Copias a Amazon S3 0 2 * * * env HOME=/root /usr/bin/duply cloud_backup backup
Duply nos permite forzar una completa cuando queramos, con el comando full, incremental con incr, purgar con purge o purge-full, etc… lo que nos permite ajustar como queramos simplemente creando crons para estos períodos personalizados. Por ejemplo, con 3 crons podríamos tener incrementales diarias, con una completa cada 15 dias, y ejecutando un purge o purge-full una vez al mes, manteniendo asi dos completas y 30 dias de incrementales.
Listando las copias disponibles
Para ver en cualquier momento el estado de nuestras copias de seguridad, basta con hacer un
duply cloud_backup status Last full backup date: Mon Oct 13 05:12:26 2014 Collection Status ----------------- Connecting with backend: BotoBackend Archive dir: /root/.cache/duplicity/duply_cloud_backup Found 0 secondary backup chains. Found primary backup chain with matching signature chain: ------------------------- Chain start time: Mon Oct 13 05:12:26 2014 Chain end time: Wed Oct 22 02:00:03 2014 Number of contained backup sets: 13 Total number of contained volumes: 13 Type of backup set: Time: Num volumes: Full Mon Oct 13 05:12:26 2014 68 Incremental Mon Oct 13 05:16:22 2014 1 Incremental Mon Oct 13 05:33:06 2014 1 Incremental Mon Oct 13 05:40:33 2014 1 Incremental Tue Oct 14 02:00:02 2014 2 Incremental Wed Oct 15 02:00:02 2014 1 Incremental Thu Oct 16 02:00:02 2014 1 Incremental Sat Oct 18 10:56:06 2014 3 Incremental Sat Oct 18 10:56:21 2014 1 Incremental Sun Oct 19 02:00:02 2014 1 Incremental Mon Oct 20 02:00:02 2014 1 Incremental Tue Oct 21 02:00:01 2014 2 Incremental Wed Oct 22 02:00:03 2014 1 ------------------------- No orphaned or incomplete backup sets found. --- Finished state OK at 04:05:20.170 - Runtime 00:00:00.859 ---
Como podemos ver, nos lista un extracto del estado de nuestras copias, tanto completas, como incrementales.
Cómo restaurar una copia
Recuperación completa
Podemos restaurar una copia con el comando restore de Duply. Es importante hacerlo como root o con sudo para que Duplicity pueda restaurar los metadatos originales del sistema de archivos, tales como permisos, propietarios, etc… este comando de ejemplo restaura la última copia a una carpeta definida, que no es necesario crear primero, ya que Duplicity lo hará por nosotros.
sudo duply cloud_backup restore /copia_recuperada
Recuperación parcial
Podemos usar el comando fetch para recuperar un archivo concreto.
sudo duply cloud_backup fetch etc/password /tmp/password
Podemos hacer lo mismo con una carpeta
sudo duply cloud_backup fetch etc /tmp/etc
Recuperación en una fecha específica
Cada comando de recuperación acepta una fecha, permitiéndonos recuperarnos en un momento concreto del pasado. Primero, utilizamos el comando status para ver qué fechas de copia tenemos disponibles:
sudo duply cloud_backup status Number of contained backup sets: 2 Total number of contained volumes: 2 Type of backup set: Time: Num volumes: Full Sat Oct 8 07:38:30 2014 1 Incremental Sat Oct 9 07:43:17 2014 1
En este ejemplo, recuperaremos la copia del dia 8; la única pega es que tendremos que escribir la fecha en formato w3.
sudo duply cloud_backup restore /copia_recuperada '2014-10-08T07:38:30'
Conclusión
Este sistema nos permite, con una línea de comandos sencilla gracias a Duply, acceder a toda la potencia de Duplicity y almacenar en los servidores de Amazon S3, con copias incrementales seguras, y obteniendo así una paz de espíritu considerable. Ya solo nos queda decir…

7 comentarios en “Copias de seguridad incrementales de forma automática en Amazon S3 con Duplicity y Duply”